datalake-archi
Best practice
- Use Event-Sourcing to facilitate backups (store now, analyze later)
- Layer data based on user’s skills (data analytic, engendering, ...)
- Keep the Datalake open (avoiding vendor lock-in, or overbalance on a single tool or database)
- Plan for performance
- See the link
Architecture (patterns)
-
Datalake
- Pros:
- Store raw data
- Store different type of data (structured, semi and non-structured)
- Allows flexibly
- Cons:
- Multiples issues of data quality
- Pros:
-
Lambda
- Batch layer
- Realtime layer
- Serving layer
-
Kappa
- Simplify lamda architecture by fusionionning batch realtime layers
-
Partitioning
- Enables efficient data filtering and retrieval, as queries can skip irrelevant partitions during processing, which is also referred to as data pruning.
- Choose frequently used columns
- Two types
- Static
- Dynamic
- Partition size should be balanced to avoid data skew
-
Bucketing
- Bucketing improves query performance by grouping similar data together and reducing the number of files to scan during processing
- Reduce the number of files to scan and improves data locality
Drawbacks
- Do not enforce data quality
- Do not support transactions
- Lake of consistency and isolation
Example of data ingestion in Uber
-
Decouple storage from query layer, each can be scaled independently
-
Two dataset types
- Append-only
- Append-plus-update
-
Challenges
-
Not read the hole dataset
-
Spread across multiple files within partitions to leverage high parallelism during writes and in case of files updates, limiting write footprint only to the files containing these updates
-
For efficient updates: lookup tool (lookup table) for location of the data with the Big data platform
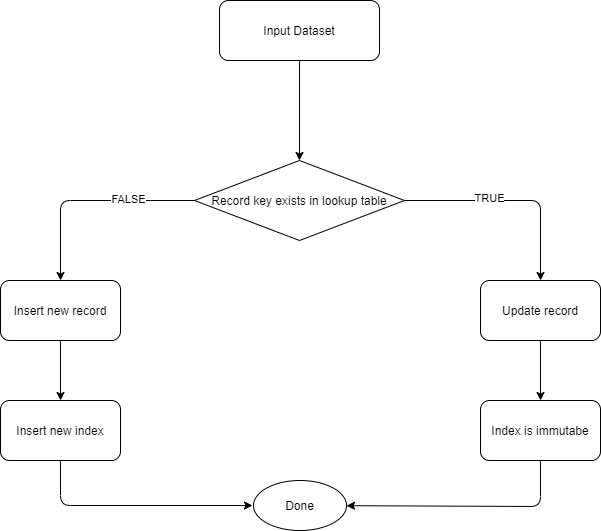
-
The indexing system that maybe used HBase or Cassandra
-
Hbase vs Cassandra
- HBase permits consistency on reads and writes. No need to tweak consistency parameter as is done in cassandra
- HBase provides automatic re-balancing of tables within a cluster
-
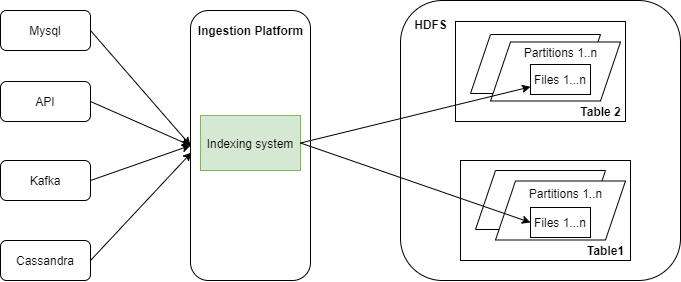
- See the link