Data Governance Tools
Data governance tools help organizations understand, protect, and improve the data they collect and use. They usually support a few core capabilities: classification, cataloging, policy management, data quality, lineage, and encryption.
Enterprise Dictionary
An enterprise dictionary defines the business vocabulary used to describe data. It helps teams agree on names, ownership, sensitivity, and expected usage.
Common dictionary objects include:
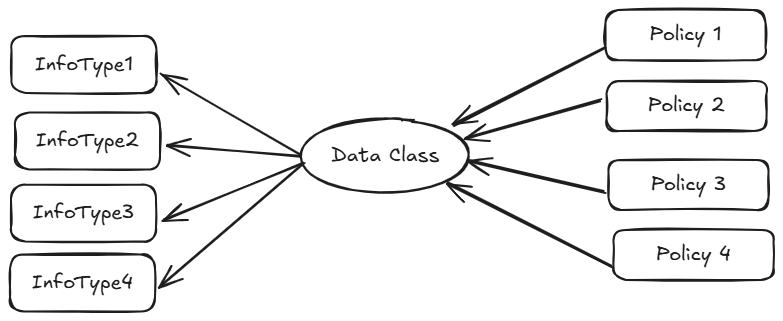
- Infotype: a specific kind of information, such as email address, Social Security number, account balance, or treatment detail.
- Data class: a group of related infotypes handled with the same governance rules.
- Policy: a rule that defines who can access a data class, how it can be used, where it can be stored, and how long it must be retained.
Data Classes
A data class groups infotypes that require similar treatment. For example, email address, postal address, and ZIP code can be grouped as personally identifiable information and protected with the same access and retention rules.
Example classification model:
- Restricted
- PII: email, name, national identifier
- PHI: diagnosis, treatment details
- Sensitive
- Financial data: bank account, credit card number
- Business data: contracts, pricing, internal reports
- Unrestricted
- Public product information
- Open reference data
Data classes are usually maintained by a central governance, security, or compliance team because policies can affect legal obligations and audit requirements.
Policy Management
An organization must be able to answer: What kind of data do we process, and what are we allowed to do with it?
A policy book records:
- The data classes used by the organization.
- The types of data processed in each class.
- The approved processing activities.
- The users, systems, and external parties allowed to access the data.
- Retention rules that define how long data is preserved.
- Residency or locality rules, when applicable.
- Usage restrictions for analytics, machine learning, sharing, or export.
Policies should be mapped to enforcement points, such as identity and access management, data masking, encryption, retention jobs, and audit logging.
Data Classification
Classification tools detect and label sensitive data. They can scan databases, files, object storage, and data warehouses to identify values such as names, emails, payment card numbers, health information, or credentials.
Common capabilities:
- Pattern matching and machine-learning-based detection.
- Labels or tags applied to datasets and columns.
- Risk scoring by dataset, owner, or storage location.
- Alerts when sensitive data appears in unexpected places.
Example services include Google Cloud Sensitive Data Protection and Amazon Macie.
Data Catalog and Metadata Management
Metadata is information about data: ownership, schema, freshness, quality, sensitivity, lineage, and business meaning.
A data catalog provides a searchable inventory of data assets. It helps data consumers find trusted datasets and understand how to use them correctly.
Useful catalog features:
- Dataset ownership and stewardship.
- Business glossary terms.
- Schema and column-level descriptions.
- Classification labels.
- Usage examples and sample queries.
- Links to lineage and quality checks.
Data Assessment and Profiling
Profiling tools inspect datasets to understand their shape and risks before they are used.
Typical profiling checks include:
- Row counts and null rates.
- Distinct values and duplicate detection.
- Min, max, average, and distribution checks.
- Format validation for dates, emails, phone numbers, and identifiers.
- Detection of unexpected sensitive values.
Profiling is useful during onboarding, migration, data quality reviews, and compliance audits.
Data Quality
Data quality tools make data measurably trustworthy for reporting, analytics, and operational systems.
Common quality dimensions:
- Accuracy: values correctly represent the real-world entity.
- Completeness: required fields are present.
- Consistency: the same concept has the same value across systems.
- Timeliness: data is fresh enough for its intended use.
- Validity: values match expected formats and domains.
- Uniqueness: duplicate records are controlled.
Quality checks should produce metrics, alerts, and ownership workflows so issues can be assigned and resolved.
Data Lineage
Lineage tracking shows how data moves and transforms across systems. It helps teams:
- Understand the reliability of dashboards and aggregated metrics.
- Trace sensitive data to prevent accidental exposure.
- Assess the impact of upstream schema or logic changes.
- Debug failed pipelines and unexpected metric changes.
- Support audit and compliance investigations.
Advanced lineage tools track history over time, not only the current inputs to a dashboard or table.
Key Management and Encryption
Encryption protects data by making it unreadable without the correct key. It is usually applied in two places:
- At rest: data stored in databases, files, disks, backups, or object storage.
- In transit: data moving over a network, usually protected with TLS.
Key management systems control encryption keys and define who or what can use them. Strong governance requires rotation, access logging, separation of duties, and clear ownership of keys.
Encryption does not replace access control, classification, or auditing. It adds another protection layer for sensitive data.