Reading and Writing in Apache Iceberg
Iceberg provided high-performance queries during reads and writes.
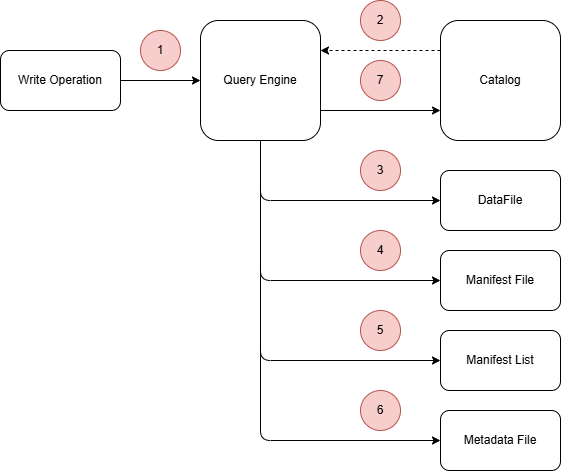
Query Engine Interaction with iceberg layer
Catalog layer
A catalog holds a pointer to the last metadata file
Metada layer
- Metadata file: Each time a query engine write a new metadata file is created atomically and is defined as the latest version metadata file
- Manifest list: Query engines interact with the manifest lists to get information about partition specifications that help them skip the nonrequired manifest files for faster performance.
- Manifest file: Finally, information from the manifest files, such as upper and lower bounds for a specific column, null value counts, and partition-specific data, is used by the engine for file pruning.
Data layer
Query engines filter through the metadata files to read the datafiles required by a particular query efficiently. On the write side, datafiles get written on the file storage, and the related metadata files are created and updated accordingly.
Apache Iceberg provides a robust process for reading and writing data, ensuring consistency, scalability, and efficient query performance.
Writing Data in Iceberg
The writing workflow in Iceberg involves several coordinated steps:
- Submit the query: The query engine receives an insert, update, or delete request.
- Fetch the latest metadata file: The engine retrieves the most recent metadata file to ensure it operates on the latest table state (to learn about the current table schema and partitioning scheme to orgnize data accordilly while writing)
- Write data files: New or updated data is written to data files in supported formats (e.g., Parquet, Avro, ORC). Data is sotred before getting written if a sort was defined.
- Create manifest files: Manifest files are generated to track the new data and delete files, including relevant statistics.
- Create manifest list: A manifest list is assembled, referencing all manifest files for the current operation.
- Write new metadata file: A new metadata file is created, capturing the updated table schema, partitioning, and snapshot information.
- Update the metadata pointer: At this stage, the engine verifies that no write conflicts have occurred. Once the check passes, it updates the catalog to reference the newest metadata file, making the changes immediately visible to all readers.
When a table is first created, only the metadata file exists. Because the initial snapshot does not reference any manifest files, there is no manifest list and no manifest files yet—simply because no data files have been written.
Reading Data in Iceberg
The reading workflow ensures that queries access the most up-to-date and relevant data:
- Query the catalog: The query engine requests the current metadata file from the catalog and get schema inforamtion to prepare , chech catalog to check current metada version
- Retrieve the current snapshot: The engine obtains the current snapshot ID and the location of its manifest list. its internal memory structures for reading the data . Then it learns about the table’s partitioning scheme to understand how the data is organized. The query engine can later leverage this to skip irrelevant datafiles. One of the most important pieces of information that the engine retrieves from the metadata file is the current-snapshot-id. This is what signifies the current state of the table. Based on the current-snapshot-id, the engine will locate the manifest list filepath from the snapshots array to traverse further and scan the relevant files.
- Access manifest files: Manifest files are read from the manifest list to identify relevant data and delete files.
- Apply partition filters: The engine uses partition information and statistics from manifest files to prune unnecessary data files.
- Read matching data files: Only the required data files are read, returning the filtered results to the user.
Iceberg’s read and write processes are designed for reliability, atomicity, and performance, supporting concurrent operations and efficient analytics at scale.